UPTR Control Plane
UPTR Control Plane ist eine Softwarelösung für zentrales IT/OT Lifecycle Management und die zentrale Steuerung verteilter IT/OT-Infrastrukturen.
Sie dient als zentrale Architekturebene für zustandsbasierte IT/OT-Operationen.
UPTR richtet Infrastrukturen kontinuierlich an einem definierten Soll-Zustand aus und steuert Lifecycle-Workflows über Provisioning, Configuration, Updates, Governance und Decommissioning hinweg – für kontrollierte, transparente und nachvollziehbare Abläufe über Edge-, Data-Center- und Cloud-Umgebungen hinweg.
Warum moderne Infrastrukturmodelle nach und nach die Kontrolle verlieren
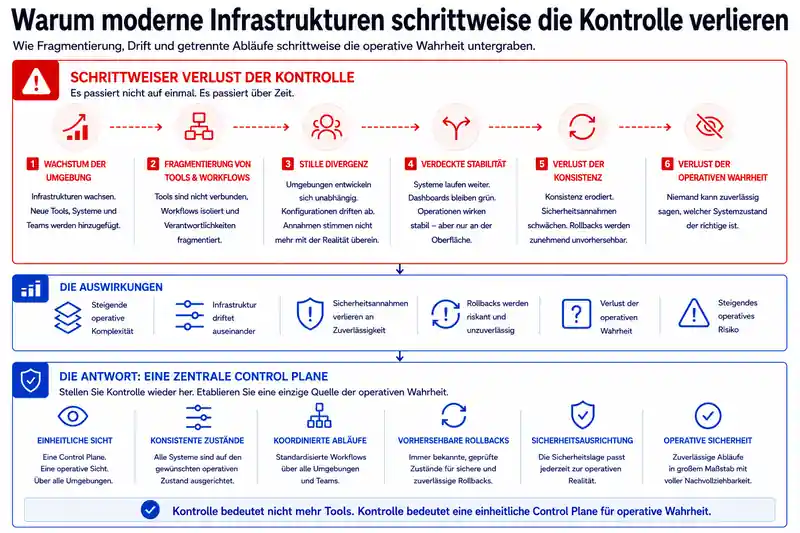
Moderne IT/OT-Infrastrukturen verlieren selten schlagartig die Kontrolle.
Der Kontrollverlust beginnt meist langsam und nahezu unbemerkt. Traditionelle Infrastrukturmodelle wurden nie dafür entwickelt, operative Konsistenz dauerhaft über hoch verteilte und sich kontinuierlich verändernde Umgebungen hinweg aufrechtzuerhalten.
Mit zunehmender Größe einer Infrastruktur entstehen zusätzliche Automatisierungswerkzeuge, isolierte Workflows und fragmentierte Verantwortlichkeiten. Unterschiedliche Umgebungen entwickeln sich unabhängig voneinander weiter, Konfigurationen driften auseinander und operative Annahmen stimmen zunehmend nicht mehr mit dem tatsächlichen Zustand der Systeme überein.
Anfangs wirken die Betriebsabläufe weiterhin stabil. Systeme laufen, Dashboards bleiben grün und es gibt kaum sichtbare Hinweise auf Probleme.
Doch unter der Oberfläche verliert die Infrastruktur schrittweise ihre Konsistenz. Sicherheitsannahmen werden unzuverlässiger, Rollbacks werden zunehmend unvorhersehbar und irgendwann kann niemand mehr sicher sagen, welcher Systemzustand eigentlich der richtige ist.
Genau hier beginnt operative Instabilität, und genau deshalb benötigen moderne Infrastrukturen zunehmend eine zentrale Conrol Plane statt isolierter Einzelwerkzeuge.
Kontrolle über fragmentierte IT/OT-Umgebungen
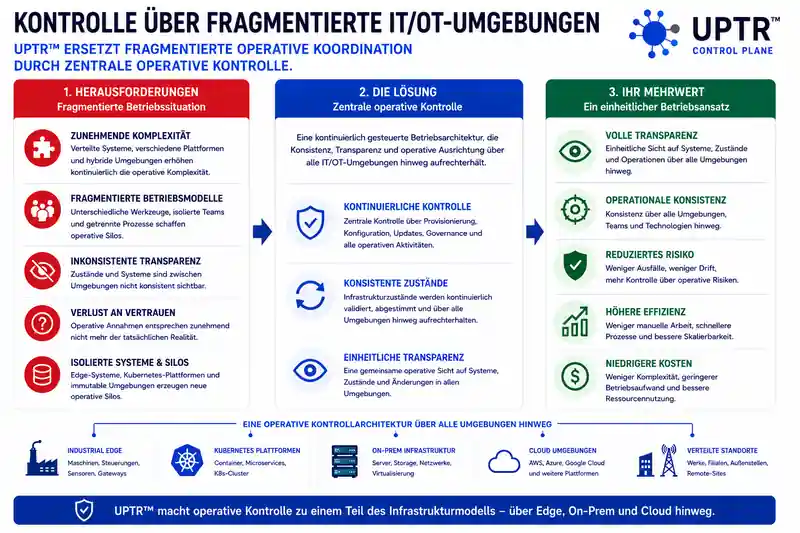
Moderne Infrastrukturen existieren heute nur noch selten in einer einzelnen zentralisierten Umgebung. Industrial-Edge-Systeme, Kubernetes-Plattformen, hybride Infrastrukturen und verteilte Betriebsstandorte erhöhen kontinuierlich die operative Komplexität innerhalb der gesamten IT/OT-Landschaft.
Gleichzeitig entwickeln sich klassische Betriebsmodelle häufig zu fragmentierten operativen Strukturen. Unterschiedliche Werkzeuge verwalten unterschiedliche Teile der Infrastruktur. Teams arbeiten isoliert voneinander. Die Transparenz über Systeme und Zustände wird zwischen Umgebungen zunehmend inkonsistent. Mit der Zeit verlieren Organisationen das Vertrauen darin, ob operative Annahmen überhaupt noch der tatsächlichen Realität entsprechen.
UPTR ersetzt fragmentierte operative Koordination durch zentrale operative Kontrolle über verteilte IT/OT-Umgebungen.
Anstatt voneinander getrennte Betriebsprozesse manuell zu koordinieren, entsteht eine kontinuierlich gesteuerte Betriebsarchitektur, in der Konsistenz, Transparenz und operative Ausrichtung über die gesamte Infrastruktur hinweg aufrechterhalten werden.
Industrielle Systeme und entfernte Edge-Standorte lassen sich dabei nach demselben Betriebsmodell verwalten wie zentrale Infrastrukturumgebungen. Kubernetes-Plattformen werden Teil derselben operativen Kontrollarchitektur, anstatt neue operative Silos zu erzeugen.
Image-basierte und immutable Systeme wie bootc-Umgebungen können in ein kontinuierlich gesteuertes Betriebsmodell integriert werden, in dem Updates zu kontrollierten operativen Releases werden und nicht zu isolierten technischen Einzelereignissen.
Operative Kontrolle hängt dadurch nicht länger von individuellem Expertenwissen oder isolierter Betriebserfahrung ab. Sie wird Teil des Infrastrukturmodells selbst.
So entsteht eine einheitliche operative Kontrollarchitektur über Edge-, On-Prem- und Cloud-Umgebungen hinweg.
Ein gewünschter Zustand. Eine operative Wahrheit.

Operative Instabilität beginnt nur selten mit einem sichtbaren Ausfall. Meistens beginnt sie deutlich früher.
Eine kleine Konfigurationsabweichung zwischen Umgebungen. Eine nicht validierte operative Änderung. Eine Abhängigkeit, die sich in Produktion anders verhält als erwartet. Ein Rollback, das zwar die Anwendungsversion wiederherstellt - aber nicht den zugrunde liegenden Infrastrukturzustand vollständig.
Mit der Zeit summieren sich diese Inkonsistenzen unbemerkt. Irgendwann verhält sich Infrastruktur nicht mehr vorhersehbar.
Deshalb ist operative Konsistenz heute zu einer der kritischsten Anforderungen moderner Infrastruktur- und IT/OT-Operations geworden.
UPTR betreibt Infrastruktur über zentral definierte und kontinuierlich abgeglichene Systemzustände. Anstatt Provisionierung, Konfiguration und Updates als voneinander getrennte operative Einzelprozesse zu behandeln, etabliert UPTR ein durchgängig abgestimmtes Betriebsmodell über die gesamte Infrastruktur hinweg.
Der gewünschte Betriebszustand wird dabei zum zentralen operativen Referenzpunkt für Rollouts, Validierungen und Infrastrukturentscheidungen. Jede Konfiguration, Abhängigkeit, Richtlinie und operative Baseline wird kontinuierlich gegen diese operative Wahrheit geprüft.
Die UPTR Control Plane koordiniert diesen Prozess über Systeme, Umgebungen und operative Domänen hinweg. Operative Drift wird kontinuierlich erkannt und korrigiert, bevor aus versteckten Inkonsistenzen systemische operative Risiken entstehen.
Gerade in modernen verteilten Infrastrukturen wird dies besonders wichtig, wenn Edge-Umgebungen, hybride Plattformen und Kubernetes-basierte Systeme über unterschiedliche Standorte und Infrastrukturebenen hinweg konsistent betrieben werden müssen.
Typische operative Inkonsistenzen können sein:
🔸 Eine Kubernetes-Umgebung verhält sich anders als die Staging-Plattform, obwohl beide denselben Release ausführen sollen.
🔸 Ein entfernter Edge-Standort arbeitet wochenlang mit veralteten Konfigurationsrichtlinien weiter, weil operative Drift unentdeckt blieb.
🔸 Ein Rollback stellt zwar die Anwendungsversion wieder her, während zugrunde liegende Infrastrukturabhängigkeiten weiterhin inkonsistent bleiben.
🔸 Infrastrukturänderungen werden in einer Umgebung erfolgreich ausgerollt, verhalten sich im produktiven Betrieb jedoch anders als erwartet.
🔸 Verteilte Betriebsstandorte entfernen sich schrittweise von der ursprünglich validierten Infrastruktur-Baseline.
Diese Situationen wirken anfangs selten kritisch - untergraben jedoch mit der Zeit schrittweise operative Zuverlässigkeit, Transparenz und Vertrauen innerhalb der gesamten Infrastruktur.
Änderungen werden zentral orchestriert. Infrastrukturzustände bleiben kontinuierlich beobachtbar, validierbar und konsistent ausgerichtet.
Dadurch werden Infrastruktur-Operationen von reaktivem Systemmanagement zu einem kontrollierten und kontinuierlich gesteuerten Betriebsmodell transformiert.
Die Architektur von UPTR
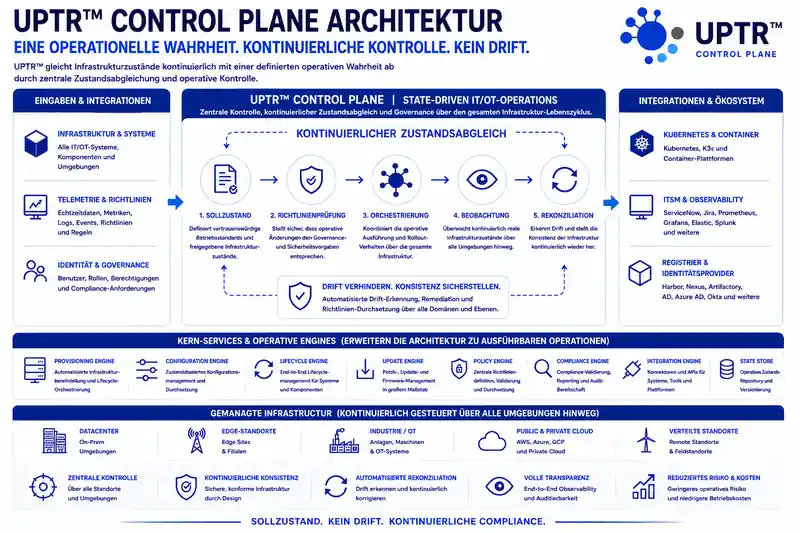
Die Architektur von UPTR basiert auf kontinuierlicher Zustandskoordination und operativer Reconciliation.
Anstatt Infrastruktur über voneinander getrennte operative Einzelprozesse zu verwalten, gleicht UPTR Systeme kontinuierlich mit einer definierten operativen Wahrheit ab.
Infrastrukturzustände werden über Umgebungen, operative Domänen und Infrastrukturebenen hinweg kontinuierlich validiert, beobachtet und abgeglichen. Dadurch bleiben Infrastruktur-Operationen selbst in verteilten IT/OT-Umgebungen vorhersehbar, konsistent und operativ abgestimmt.
Operative Änderungen, Infrastrukturrichtlinien und Rollout-Prozesse bleiben dabei durch zentrale operative Kontrolle kontinuierlich koordiniert. Versteckte operative Drift kann dadurch erkannt und korrigiert werden, bevor aus Inkonsistenzen operative Instabilität oder systemische Infrastrukturrisiken entstehen.
Gleichzeitig entsteht eine operative Kontrollarchitektur, in der Infrastrukturzustände nicht nur bereitgestellt, sondern dauerhaft überwacht, validiert und konsistent gehalten werden. Infrastruktur wird dadurch zu einem kontinuierlich gesteuerten Betriebsmodell - anstatt zu einer Sammlung isolierter administrativer Einzelprozesse.
Im Zentrum dieser Architektur steht die UPTR Control Plane, die ein kontinuierlich gesteuertes Betriebsmodell für zustandsbasierte IT/OT-Lifecycle-Prozesse bereitstellt und auf fünf zentralen operativen Mechanismen basiert:
🔹 Desired State ➜ Definiert vertrauenswürdige Betriebszustände und freigegebene Infrastruktur-Baselines.
🔹 Policy Validation ➜ Stellt sicher, dass operative Änderungen Governance- und Sicherheitsvorgaben entsprechen.
🔹 Orchestration ➜ Koordiniert operative Ausführung und Rollout-Verhalten über die gesamte Infrastruktur hinweg.
🔹 Observation ➜ Überwacht kontinuierlich reale Infrastrukturzustände über Umgebungen hinweg.
🔹 Reconciliation ➜ Erkennt Drift und stellt Infrastrukturkonsistenz kontinuierlich wieder her.
Gemeinsam bilden diese operativen Mechanismen die Grundlage für kontinuierlich gesteuerte Infrastruktur-Operationen über Edge-, On-Prem- und Cloud-Umgebungen hinweg.
Die folgenden Core Services und Operational Engines realisieren die operativen Funktionen der UPTR Control Plane und sorgen für die kontinuierliche Umsetzung des gewünschten Systemzustands über den gesamten IT/OT-Lifecycle hinweg.
Zentrale Services & Operative Engines der UPTR Control Plane
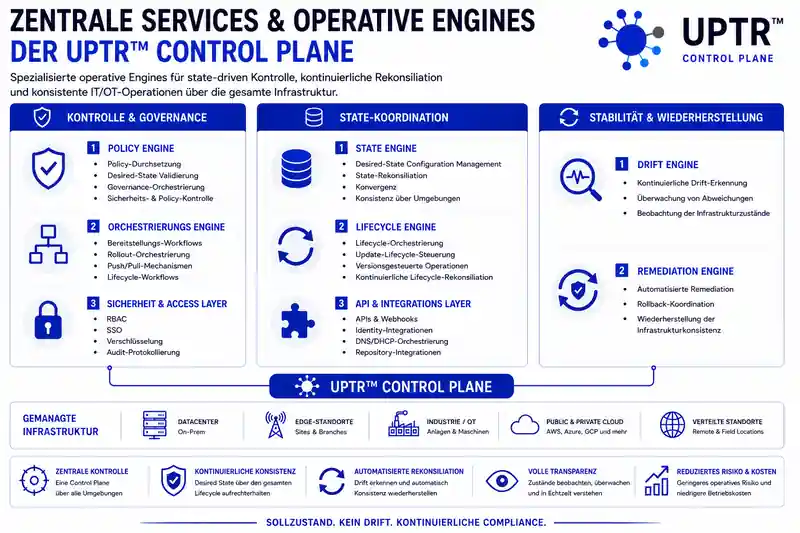
Die UPTR Control Plane kombiniert spezialisierte operative Engines, um Provisionierung, Konfigurationsmanagement, Update-Orchestrierung, Governance und Lifecycle-Konsistenz über verteilte IT/OT-Infrastrukturen hinweg kontinuierlich zu steuern.
Kontrolliertes IT/OT Lifecycle Management entsteht nicht automatisch.
Es erfordert dedizierte operative Services, die Infrastrukturzustände kontinuierlich validieren, Änderungen orchestrieren, Drift erkennen, Richtlinien durchsetzen und operative Konsistenz über alle Umgebungen hinweg wiederherstellen.
Operative Aktivitäten bleiben dadurch nicht länger isolierte technische Aufgaben, die unabhängig voneinander durch Teams und Systeme ausgeführt werden. Stattdessen werden sie zu kontinuierlich koordinierten Betriebsprozessen, die durch zentrale Kontrolle, Zustandsbewusstsein und infrastrukturbasierte Richtlinien gesteuert werden.
Um dieses Betriebsmodell umzusetzen, organisiert die UPTR Control Plane ihre operativen Engines in drei funktionale Steuerungsbereiche: Kontrolle & Governance, State-Koordination sowie Stabilität & Wiederherstellung. Diese Bereiche bilden ab, wie Infrastruktur-Operationen in der Praxis tatsächlich funktionieren - operative Entscheidungen müssen zunächst gesteuert und validiert werden, Infrastrukturzustände müssen kontinuierlich abgestimmt bleiben und operative Abweichungen müssen erkannt und korrigiert werden, bevor sie zu systemischen Infrastruktur-Risiken werden.
Gemeinsam schaffen diese operativen Bereiche eine kontinuierlich gesteuerte Kontrollarchitektur, in der Infrastruktur-Operationen über den gesamten Lifecycle hinweg vorhersehbar, transparent und operativ abgestimmt bleiben.
Genau so schließt die UPTR Control Plane den Lifecycle-Kreislauf.
Infrastruktur-Operationen entwickeln sich dadurch von isolierten administrativen Tätigkeiten hin zu einem kontinuierlich gesteuerten operativen System, in dem Konsistenz, Transparenz und Kontrolle über den gesamten Infrastruktur-Lifecycle erhalten bleiben.
Services & Features der UPTR Control Plane
Control & Governance
Policy Engine
Validiert Infrastruktur kontinuierlich gegen Governance-, Compliance- und Betriebsrichtlinien.
🔹 Policy Enforcement & Compliance-Validierung
🔹 Desired-State-Validierung
🔹 Governance-Orchestrierung
🔹Sicherheits- und Richtlinienkontrolle
🔹 Auditfähige operative Konsistenz
Orchestration Engine
Koordiniert und automatisiert Infrastruktur-Workflows über verteilte Systeme und Standorte hinweg.
🔹 Automatisierte Provisionierungs-Workflows
🔹 Bare-Metal- & Edge-Provisionierung
🔹 Rollout-Orchestrierung
🔹 Push-/Pull-basierte Ausführungsmechanismen
🔹 AutoYaST-, Kickstart- & Preseed-Integration
🔹 Lifecycle-gesteuerte operative Workflows
Security & Access Layer
Stellt zentrale Zugriffskontrolle, Nachvollziehbarkeit und Auditierbarkeit sicher.
🔹 Rollenbasierte Zugriffskontrolle (RBAC)
🔹 LDAP-Integration
🔹 Benutzer- & Rollenverwaltung
🔹 Audit Logging & Event Monitoring
🔹 Operative Nachvollziehbarkeit
🔹 Governance- & Compliance-Transparenz
State Coordination
State Engine
Sichert Infrastrukturkonsistenz durch kontinuierliche Desired-State-Reconciliation.
🔹 Desired-State Configuration Management
🔹 State Reconciliation & Konvergenz
🔹 Versionskontrollierte Infrastrukturzustände
🔹 Konsistente Konfigurationszustände über Umgebungen hinweg
🔹 Kontinuierliche operative Synchronisierung
Lifecycle Engine
Koordiniert Infrastruktur-Lifecycle-Operationen durch kontinuierlich gesteuerte und zustandsbasierte Lifecycle-Ausführung.
🔹 Lifecycle-gesteuerte Provisionierungs-Workflows
🔹 Kontinuierliche Abstimmung von Konfigurations-Lifecycles
🔹 Kontrollierte Orchestrierung von Update-Lifecycles
🔹 Koordination von Infrastruktur-Übergängen
🔹 Desired-State-basiertes Lifecycle-Management
🔹 Versionskontrollierte Lifecycle-Operationen
🔹 Kontinuierliche Lifecycle-Reconciliation
🔹 Automatisierte Lifecycle-Ausführung
🔹 Lifecycle-Konsistenz über unterschiedliche Umgebungen hinweg
🔹 Lifecycle-Governance
API & Integration Layer
API & Integration Layer verbinden die UPTR Control Plane mit bestehenden Infrastruktur-, Identity- und Automatisierungssystemen.
🔹 Native Ansible-Integration
🔹 Integriertes IP Address Management (IPAM)
🔹 DNS- & DHCP-Orchestrierung
🔹 API- & Webhook-Integrationen
🔹 LDAP- & Identity-Provider-Integration
🔹 Repository- & Software-Source-Integration
🔹 Infoblox-, Active Directory- & BIND-Integration
Stability & Recovery
Drift Engine
Erkennt versteckte Infrastrukturabweichungen, bevor daraus operative Risiken entstehen.
🔹 Kontinuierliche Drift-Erkennung
🔹 Überwachung operativer Abweichungen
🔹 Infrastruktur-State-Observability
🔹 Validierung von Umgebungskonsistenz
🔹 Früherkennung operativer Risiken
Remediation Engine
Stellt Infrastrukturkonsistenz automatisiert durch kontrollierte Remediation-Workflows wieder her.
🔹 Automatisierte Remediation
🔹 Rollback-Koordination
🔹 State-Recovery-Workflows
🔹 Wiederherstellung operativer Konsistenz
🔹 Kontrollierte operative Recovery-Prozesse
Unterstützte Plattformen & Funktionen
Die UPTR Control Plane unterstützt heterogene IT/OT-Infrastrukturen über Datacenter-, Cloud- und verteilte Edge-Umgebungen hinweg.
Unterstützte Betriebssysteme
⬢ AlmaLinux
⬢ Debian
⬢ Ubuntu
⬢ Red Hat Enterprise Linux (RHEL)
⬢ Rocky Linux
⬢ SUSE Linux Enterprise Server (SLES)
⬢ Fedora
⬢ Oracle Linux
⬢ CentOS
Unterstützte Infrastrukturplattformen
⬢ Bare-Metal-Systeme
⬢ Edge-Infrastrukturen
⬢ VMware vSphere
⬢ Proxmox
⬢ oVirt
⬢ Public & Private Cloud Umgebungen
Operative Plattformfunktionen
⬢ Moderne Angular-basierte Web UI & Dashboard
⬢ Zentrale Task- & Scheduler-Steuerung
⬢ Statische & dynamische Infrastrukturgruppen
⬢ Infrastrukturweite Suche & Transparenz
⬢ Kontrollierte Lifecycle-Operationen über verteilte Umgebungen hinweg
Herausforderungen, die durch die Control Plane adressiert werden
Moderne IT/OT-Umgebungen erzeugen operative Herausforderungen, die selten isoliert auftreten. Sie entstehen gleichzeitig über Systeme, Umgebungen und Teams hinweg und erhöhen die operative Komplexität über den gesamten Lifecycle.
Die UPTR Control Plane adressiert diese Herausforderungen durch zustandsbasierte Orchestrierung, Lifecycle-Kontrolle und vorhersehbare Systemprozesse:
👉 Konfigurationsdrift & gewünschter Systemzustand
Konsistente Systemzustände durch definierte und durchsetzbare Zielkonfigurationen sicherstellen.
👉 Update-Risiken & Lifecycle-Kontrolle
Operative Risiken durch kontrollierte Updates, versionierte Zustände und zuverlässige Rollback-Mechanismen reduzieren.
👉 Sicherheit, Compliance & Transparenz
Transparenz und Nachvollziehbarkeit durch richtlinienbasierte Prozesse und konsistente Systemzustände erhöhen.
👉 Verantwortlichkeiten & operative Komplexität
Ein einheitliches Betriebsmodell über Technologien, Systeme und Teams hinweg schaffen.
👉 Edge- und verteilte Infrastrukturen
Vorhersehbare und skalierbare Prozesse über verteilte und geografisch getrennte Umgebungen ermöglichen.
Lifecycle Outcomes & Operative Vorteile
Die UPTR Control Plane verwandelt isolierte operative Aufgaben in ein kontinuierlich kontrolliertes Lifecycle-System - von der initialen Bereitstellung bis zur kontrollierten Außerbetriebnahme.
✔️ Kontinuierliche operative Konsistenz
✔️ Automatisierte Drift-Erkennung & Reconciliation
✔️ Kontrollierte Infrastruktur-Rollouts
✔️ Zentrale Governance & Compliance
✔️ Vorhersehbares Infrastrukturverhalten
✔️ Reduzierung operativer Risiken
✔️ Kontrolliertes Lifecycle Cleanup & Decommissioning
✔️ Vollständige Infrastrukturtransparenz & Auditierbarkeit
Strategische Perspektive
Technologie allein löst keine operative Komplexität.
Erfolgreiche Umsetzung erfordert zusätzlich strategische Ausrichtung, organisatorische Abstimmung und Geschäftsentwicklung.
APILANi agiert als Alliance Partner für die strategische Positionierung, Geschäftsentwicklung und Markterschließung von UPTR in EMEA. Mehr über APILANi.
Von Architektur zu Betrieb
UPTR zeigt, wie zentrale operative Kontrolle über komplexe und verteilte Infrastrukturumgebungen hinweg etabliert werden kann.
Das Ergebnis sind kontrollierte Lifecycle-Ausführung, operative Transparenz und kontinuierlich gesteuerte Infrastrukturzustände über große Betriebsumgebungen hinweg.